The Structure of the Presentation

- History of blogging APIs
- Basic operation of the Atom Publishing Protocol
- Applications to areas outside weblogs
History of Blogging APIs

LiveJournal
- One of the earliest weblog updating protocols.
- Uses 'application/x-www-form-urlencoded' encoded data sent to the server.
- The response is encoded as a series of key/value pairs separated by newlines.
- Called The LiveJournal Flat Client/Server Protocol
LiveJournal (Example Request)
POST /interface/flat HTTP/1.0
Host: www.livejournal.com
Content-type: application/x-www-form-urlencoded
Content-length: 34
mode=login&user=test&password=testLiveJournal (Example Response)
HTTP/1.1 200 OK
Date: Sat, 23 Oct 1999 21:32:35 GMT
Server: Apache/1.3.4 (Unix)
Connection: close
Content-Type: text/plain
name
Mr. Test Account
success
OK
message
Hello Test Account!
LiveJournal Capabilities
- Create a new log entry.
- Edit/Delete an existing log entry.
- Get a list of log entries.
There are other capabilities relating to 'friend' management.
LiveJournal
While not a major protocol today it set the pattern.
- Everything is done through HTTP POST
- Everything goes through one URI
- Does not use HTTP Authentication
LiveJournal - Everything in POST
- HTTP has other methods:
- GET
- PUT
- DELETE
XML-RPC
- The ink had barely dried on the XML specification (Feb-1998) when Dave Winer introduced (Mar-1998) XML-RPC.
- Remote Procedure Call
- Uses XML over HTTP.
XML-RPC Example Request
POST /RPC2 HTTP/1.0
User-Agent: Frontier/5.1.2 (WinNT)
Host: betty.userland.com
Content-Type: text/xml
Content-length: 181
<?xml version="1.0"?>
<methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value>
<i4>41</i4>
</value>
</param>
</params>
</methodCall>
XML-RPC Request Body
<?xml version="1.0"?>
<methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value>
<i4>41</i4>
</value>
</param>
</params>
</methodCall>
- Note that this isn't really a 'document' so much as a serialization of function call parameters.
- Also note that lack of namespaces.
XML-RPC
XML-RPC follows the same patterns that the LiveJournal API set.
- Everything is done through HTTP POST
- Everything goes through one URI
- Does not use HTTP Authentication
In addition, for most of the life of the XML-RPC specification, the content of 'string' parameters transported via XML-RPC were restricted to ASCII.
XML-RPC Protocols
Despite those weaknesses several popular APIs were built on ..
API is the wrong term.

- API is the wrong word.
- Interface is ok.
- Protocol is the proper word.
- I'm guilty of this as much as anyone, the early versions of the Atom Publishing Protocol were initially called the AtomAPI.
XML-RPC Based Protocols
- Despite the weaknesses...
- The Manilla-RPC Interface
- The Blogger API
- The MetaWeblog API
- The LiveJournal XML-RPC Client/Server Protocol
XML-RPC Based Protocols Evolution
XML-RPC Based Protocol Weaknesses
Mistakes were made.
Weakness - I18N
- Internationalization.

Weakness - Extensibility
- XML-RPC based protocols aren't easily extensible.
- No understanding of XML namespaces.
Weakness - Authentication
- No HTTP Authentication.
- Plain text passwords.
Weakness - Features
One of the protocols doesn't allow setting:
- Dates
- Titles
Weakness - Poor utilization of HTTP
- POST
- One URI
Weaknesses - Summary
XML-RPC = (XML - I18N - Extensibility) + (HTTP - Methods - Auth - URIs).
Enter the Atom
- IETF WG officially known as "Atom Publishing Format and Protocol (atompub)"
- Deliverables:
- A syndication format. Proposed Standard as of August 2005.
- An editing protocol.
- Oct 05 Request Last Call for APP
- Nov 05 Submit APP to IESG for consideration as a Proposed Standard
- Ooops
Workgroup Products
- Protocol leverages the Format.
Atom Syndication Format Example
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Example Feed</title>
<link href="http://example.org/"/>
<updated>2003-12-13T18:30:02Z</updated>
<author> <name>John Doe</name> </author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href="http://example.org/2003/12/13/atom03"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<content type="xhtml" xml:lang="en">
<div xmlns="http://www.w3.org/1999/xhtml">
<p><i>[Update: The Atom draft is finished.]</i></p>
</div>
</content>
</entry>
</feed>
Atom Syndication Format Highlights
- Namespaces!
- Titles
- Entries
Let's look closer at an 'entry'
<?xml version="1.0" encoding="utf-8"?>
<entry xmlns="http://www.w3.org/2005/Atom">
<title>A Simple Title</title>
<link href="http://example.org/2003/12/13/atom03"/>
<author>
<name>Marge Inoverrah</name>
</author>
<id>http://example.org/2003/32397</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary type="text">The history and lore of Lorem Ipsum.</summary>
<content type="text">Lorem Ipsum Dolor...</content>
</entry>The Entry
- Contains the basic information needed for an entry.
- 'Document Literal' vs serialized function parameters.
- Is valid Atom.
- Allows foreign markup.
Common actions in the Atom Publishing Protocol
- Keep the focus to the same parts of the protocols we've reviewed so far:
- Create a new entry
- Edit/Delete an entry
- Get a list of entries.
- In the RPC world these were just different procedure calls.
Resources
- Give everything a URI.
- Entries and collections of entries become first class web citizens.
Edit
- So how do you edit an entry via Atom?
- Each entry has its own URI
- So do a GET on that URI.
GET
- What a novel concept, GET!
- Only 99.9% of the traffic on the web is in the form of GETs.
- Do you think the web might be optimized to handle GETs?
Get a list of entries.
- So how do you get a list of entries via Atom?
- Each Entry Collection has its own URI
- So do a GET on that URI.
Did I mention GET?
- What a novel concept, GET!
- Only 99.9% of the traffic on the web is in the form of GETs.
- Do you think the web might be optimized to handle GETs?
Delete
- So how do you delete an entry via Atom?
- Each entry has its own URI
- So do a DELETE on that URI.
- You knew all those methods would come in handy.
Common actions in the Atom Publishing Protocol - Update
- So how do you update an entry via Atom?
- Each entry has its own URI
- So do a PUT of the updated entry to that URI.
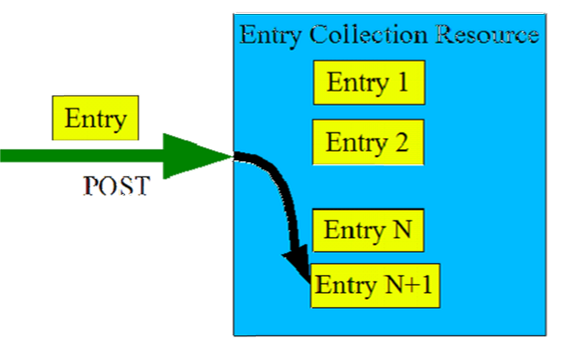
Common actions in the Atom Publishing Protocol - Create
- So how do you create an entry via Atom?
- POST the entry to the URI of the Entry Collection.
Create Info Graphic
Atom Publishing Protocol Summary
| Resource | Method | Description |
|---|---|---|
| Entry | GET | Get the latest |
| Entry | PUT | Update an entry |
| Entry | DELETE | Delete the entry |
| Collection | GET | Get a list of entries |
| Collection | POST | Create a new entry |
Examples
- Assume our Entry Collection lives at
http://example.com/reilly. - Assume each Entry lives at
http://example.com/reilly/N
Note: URIs are opaque in Atom.
Example - Get the Collection
- We are given the URI of an Entry Collection (Don't worry about how we got that URI to begin with.)
- Doing a GET on that URI returns part of the Collection.
- Note it is formatted as an Atom Feed.
Example - Get Collection - Request
GET /reilly/ HTTP/1.1
Host: example.org
Content-Type: application/atom+xmlExample - Get Collection - Response
HTTP/1.1 200 Ok Content-Type: application/atom+xml Content-Length: nnnn <?xml version="1.0" encoding="utf-8"?> <feed xmlns="http://www.w3.org/2005/Atom"> <title> Feed</title> <link rel="next" href="http://example.org/reilly/page2"/> ... <entry> <title>Atom-Powered Robots Run Amok</title> <link rel="edit" href="http://example.org/edit/07"/> ... </entry> <entry> <title>The sky is falling</title> <link rel="edit" href="http://example.org/edit/04"/> ... </entry> <entry> <title>Some other entry</title> <link rel="edit" href="http://example.org/edit/27"/> ... </entry> ... </feed>
Example - Create a new Entry
- POST to the same URI, the one for the Entry Collection.
- We are POSTing an Atom Entry.
Example - Create a new Entry - Request
POST /reilly HTTP/1.1
Host: example.org
Content-Type: application/atom+xml
<entry>
<title>Fourth Post!</title>
<id>tag:example.org,2003:3.2397</id>
<updated>2005-07-31T12:29:29Z</updated>
<author> <name>Joe Gregorio</name> </author>
<content type="xhtml" xml:lang="en">
<div xmlns="http://www.w3.org/1999/xhtml">
<p>Hello <i>World</i>!</p>
</div>
</content>
</entry>
Example - Create a new Entry - Response
HTTP/1.1 201 Created
Location: http://example.org/reilly/4
Example - Deleting an entry
- DELETE on the URI returned in the Location: header.
Example - Delete - Request
DELETE /reilly/4 HTTP/1.1
Host: example.org
Example - Delete - Response
HTTP/1.1 200 OkExample - Review
- GET on the Entry Collection resource returned a Feed of the most recent entries.
- POST on the Entry Collection resource creates a new Entry.
- GET on the Entry resource returns the entry.
- PUT on the Entry resource updates the entry.
- DELETE on the Entry resource deletes the entry.
Compare and contrast with XML-RPC protocols
- Document Literal
- Using all the verbs
- Each resource has its own URI
Document Literal
- The document is used on the wire.
- No 'serialization'.
- The same document extension mechanism is used for the protocol extension mechanism.
Using all the verbs
- Since 99.9% of the web is GET, there are some optimizations.
- GETs can be cached
- GETs can be ETag'd
- GET responses can be compressed
GET - gzip - Request
GET /reilly/4 HTTP/1.1
Host: example.org
Accept-Encoding: compress, gzip
Content-Type: application/atom+xmlGet - gzip - Response
HTTP/1.1 200 Ok
Content-Type: application/atom+xml
Content-Encoding: gzip
...gzipped stuff goes here...
Typically 1/3 of the original size.
GET - ETag - First Response
HTTP/1.1 200 Ok
Content-Type: application/atom+xml
ETag: 3948018403940943 GET - ETag - Second Request
GET /reilly/4 HTTP/1.1
Host: example.org
If-Match: 3948018403940943
Content-Type: application/atom+xmlGet - ETag - Second Response
HTTP/1.1 304 Not Modified
Content-Type: application/atom+xml We've now reduced our response body by 100%
Get - ETag/gzip - Request
Guess what this does.
GET /reilly/4 HTTP/1.1
Host: example.org
If-Match: 3948018403940943
Accept-Encoding: compress, gzip
Content-Type: application/atom+xml - Reduced our response body by 100% if the entry hasn't been updated
- Reduced it by 66% if it has been updated.
Concurrent Updates
- PUT + ETag = conditional PUT
Authentication
- See RFC 2617
- See HTTPS/TLS
Each resource has its own URI
- Can be used to blend services
- Jon Udell article Tangled in the Threads
Things not covered
- Media Collections
- Introspection
- Finding collections
- Determining collection capabilities
It's not all puppies and roses
- atom:id
- atom:updated
Applications outside weblogs
Wiki
- Each WikiWord is an Entry.
- Entries can be sorted on most recently edited.
- An Atom-Powered Wiki
APP + Microformats
- APP + hCalendar = calendaring protocol
- APP + hCard = contact list protocol
Lessons from the web
Today databases violate essentially every lesson we have learned from the Web.
- Adam Bosworth
- Simple, relaxed, sloppily extensible text formats and protocols often work better than complex and efficient binary ones.
- It is worth making things simple enough that one can harness Moore's law in parallel.
- It is acceptable to be stale much of the time.
- The wisdom of crowds works amazingly well.
Lessons from the web (continued)
Today databases violate essentially every lesson we have learned from the Web.
- Adam Bosworth
- People understand a graph composed of tree-like documents (HTML) related by links (URLs).
- Pay attention to physics.
- Be as loosely coupled as possible.
- KISS. Keep it (the design) simple and stupid.
The Atom Store
AtomStore = APP + OpenSearch
- Applications - Lots of entries, title, content, id, other.
- Scalability - A database the size of the Google corpus
- Each entry has its own URI
- Entries can link to each other
- All those cacheable GETs
The End
- The End
"Just" use WebDAV
- The stated goal of the WebDAV working group is (from the charter) to "define the HTTP extensions necessary to enable distributed web authoring tools to be broadly interoperable, while supporting user needs", and in this respect DAV is completing the original vision of the Web as a writeable, collaborative medium.
That sounds pretty close to the Atom Publishing Protocol.
"Just" use WebDAV - Locking
- Locking (concurrency control): long-duration exclusive and shared write locks prevent the overwrite problem, where two or more collaborators write to the same resource without first merging changes. To achieve robust Internet-scale collaboration, where network connections may be disconnected arbitrarily, and for scalability, since each open connection consumes server resources, the duration of DAV locks is independent of any individual network connection.
"Just" use WebDAV - Properties
- Properties: XML properties provide storage for arbitrary metadata, such as a list of authors on Web resources. These properties can be efficiently set, deleted, and retrieved using the DAV protocol. DASL, the DAV Searching and Locating protocol, provides searches based on property values to locate Web resources.
"Just" use WebDAV - Properties
- Namespace manipulation: Since resources may need to be copied or moved as a Web site evolves, DAV supports copy and move operations. Collections, similar to file system directories, may be created and listed.
Note that 'namespace' in this context refers to a servers URI namespace and not an XML namespace.
"Just" use SOAP
- One method - POST
- One URI
- Schema - 'nuff said.