 Joe Gregorio
Joe Gregorio
Last time I talked about the creation of Robaccia I got to the point of a working framework and just waved my hands and said you could keep going and "just" add conventions. I have pointed out that "just" is a dangerous word, so let's walk through the rest of the steps to building a Rails/Django-like web framework.
Update: Just so there's no confusion, the title of this post comes from The Complicator's Gloves.
They key point of adding 'conventions' is to take a load off the user. You need to actually remove two kinds of load, cognitive and manual. Cognitive load is the number of concepts you need to hold in your head. The fewer the number of concepts, and the more uniformly they are applied, the easier the system will be to use. Manual load is just the amount of manual stuff, like typing, that you need to do. Why should I have to manually create a directory structure when a computer is capable of doing that?
Motivation
Before diving into lots of code and details let's clarify what I'm trying to accomplish here. I am not trying to write Rails for Python. My mission in creating this software, and this write-up, is to lay out the core ideas of constraints, cognitive load, and manual load, and how to apply them to create a Rails/Django-like web framework, in the hopes that it is helpful, so that you can use it to create your own Rails-like framework in your language of choice.
In this example I make some design decisions that might seem a bit extreme. They are. You probably should make different choices for your web framework based on your programming language and problem domain.
The Happy Path
I am going to borrow a term from testing, Happy Path, and use it in the context of creating our conventions. We need to pick a happy path when using our framework, and we need to knock down as many barriers, and make things as easy as possible, as long as users stick to that happy path.
Design
If you are familiar with Ruby on Rails or Django then the development story should be familiar. Here's the core of our design document. Creating an employee application should consist of the following steps:
$ robaccia createproject myproject
$ cd myproject
$ robaccia addmodelview employees # Creates view, templates, and model.
$ gvim ./models/employees.py # Add table columns.
$ robaccia createdb
$ robaccia run
$ firefox http://localhost:8080/employees/
Of course, we may already have a model in place, and want to just create another view on that model. Adding a view-only collection should be as simple as:
$ robaccia addview employees
$ robaccia run
$ firefox http://localhost:8080/employees/
Preliminaries
Currently Robaccia consists of a couple modules and a bunch of conventions for how to lay out a project. They include the files:
model.py- One or more models expressed in SQLAlchemy Tables.view.py- One or more views, implemented as WSGI applications.urls.py- A single instance of a selector object that maps URIs to the WSGI applications inview.py.templates- A directory of Kid templates to be used to format the responses from the view applications.dbconfig.py- Configuration for the SQLAlchemy Tables in model.py
To accomodate making more complex projects we'll update most of those files to be directories, and add another directory for log files:
/views
/templates
/models
/logs
We'll leave urls.py as a file, but just rename it
to dispacher.py, because while it does match
based on the incoming URI, it also matches on the request method,
so let's name it for what it does.
So let's look at what the directory structure we have for a Robaccia based application:
views/ models/ templates/ logs/ dispatcher.py
And if we add a new resource to our application we distribute the model, view, and template files under each of those directories.
views/name.py models/name.py templates/name/list.html templates/name/retrieve.html ... logs/
Now Robaccia, using selector, allows you to dispatch to any view from any form of URI and any method. We need to simplify that, by adding constraints, and guide those constraints using a conceptual model. You can't possibly be surprised that I would choose a RESTful collection as an organizing principle. In particular, we'll assume that everything you want to create will fit into wsgicollection. We will, obviously, build in an escape hatch, but RESTful collections will be our happy path.
In general, using the notation of selector, we are looking at URIs of the form:
/...people/[{id}][;{noun}] And dispatching requests to URIs of that form to functions with nice names:
GET /people list()
POST /people create()
GET /people/1 retrieve()
PUT /people/1 update()
DELETE /people/1 delete()
GET /people;create_form get_create_form()
GET /people/1;edit_form get_edit_form()
We'll wrap all those target functions up into a single class and make instances of those classes a WSGI application:
from wsgicollection import Collection
class People(Collection):
# GET /people/
def list(environ, start_response):
pass
# POST /people/
def create(environ, start_response):
pass
# GET /people/1
def retrieve(environ, start_response):
pass
# PUT /people/1
def update(environ, start_response):
pass
# DELETE /people/1
def delete(environ, start_response):
pass
# GET /people/;create_form
def get_create_form(environ, start_response):
pass
# POST /people/1;comment_form
def post_comment_form(environ, start_response):
pass
So if a collection is our organizing principle, what about our URI structure? Let's keep it simple and presume everything will fall into a simple URI template:
/{view:alnum}/[{id:unreserved}][;{noun:unreserved}]
That is, each {view} represents a collection, and {view}/{id} is a member of that collection. That's very simple and we have introduced a number of constraints by restricting ourselves to this URI structure:
- Content type
- We presume that this collection has a single content type, such as HTML, or JSON. There is no provision for having a single collection serve up content in different media types. If you want to handle different media types then you can create two views that reference the same underlying model.
- Nesting
- The namespace is very flat, not allowing nesting of
resources beyond the simple collection. For example, if you were
creating blogging application, you couldn't create
the main blog as a collection of entries,
/blog/{id}, and then have a collection of comments for each blog entry, ala/blog/{id}/comments/{commentid}, but you could have a collection that worked on all comments received,/comments/{id}. Again, you can certainly do the nested collections for comments with the tools we are going to supply, but that is not on the happy path.
Also, in the intervening time since Robaccia was initially released I've written my own version of selector, wsgidispatcher, so we'll switch to using that. The activity around Kid has diminished and moved mostly to Genshi, so we will also migrate to Genshi for templating.
RESTful collections, and a highly constrained URI scheme, are the concepts we're using to reduce cognitive load. On the manual load side, we'll build some command line tools to automate the generation of stubs and directories.
Implementation
To fulfill our design we'll take the current Robaccia through a number of incremental steps. The first step is modularization.
Modularize robaccia
We need to convert Robaccia from a set of conventions and a few lines of code into a library on it's own. First, we consolidate all the code into a single installable module. We'll also create a stub for the 'robaccia-admin' program, the one we'll eventually use to create the skeleton for project.
robaccia.py => robaccia/__init__.py # controversial in some quarters wsgidispatcher.py => robaccia/wsgidispatcher.py wsgicollection.py => robaccia/wsgicollection.py mimetypes.py => robaccia/mimetypes.py
The only change that this requires in our code is a change in the imports for wsgicollection and wsgidispatcher.
Now let's create a setup.py so our new module can be installed.
This uses the built-in distutils library, and the configuration
file is really a Python program.
[setup.py]
Note that this setup file not only installs the robaccia library, but also the 'robaccia-admin' program.
robaccia-admin
We want to create a program that we can run that takes commands as arguments, just like 'svn' or 'bzr'. In addition we want help, and also, like 'bzr', a way to make the command set extensible. At the very least, we want to make adding new command to 'robaccia-admin' easy. The simplest thing that could possibly work is to have the command name match a method name in the module, and just look them up on the fly.
robaccia-bin
members = globals()
if __name__ == "__main__":
try:
cmd = sys.argv[1]
except:
cmd = "help"
args = sys.argv[2:]
if cmd not in members or
cmd.startswith("_") or (not callable(members[cmd])):
cmd = "help"
members[cmd](args)
Note that if a command isn't found in 'members', then we assume the command "help". That gets us running commands, but how do we do help? We need two kinds of help, a short message on how to use a command, used when we request a list of commands, and a longer help description for when we want help on a single command. Also, I don't want to write a separate help file.
In Python if the first thing in your method is a string, then that string is available via the __doc__ attribute. We'll put in place a convention that the first line of the doc string is a short description, and the whole doc string will be used for help on that command. So, as an example, here is the implementation for the 'commands' command. Run 'robaccia-admin commands' to get a list of all the commands that the robaccia program supports.
robaccia-bin
def commands(args):
"""robaccia commands
List all known commands that robaccia knows.
"""
for name in members:
if not name.startswith("_") and callable(members[name]):
print members[name].__doc__.splitlines()[0]
So now we can add the 'createproject' command. The 'createproject' command just creates a directory structure populated with some default files. Looking back into 'setup.py' you can see the 'package_data' parameter, which is a list of non-source files that can be packaged with the library. We will stuff a skeleton project directory structure in there and copy it over when we create a project. We'll leverage Python's ability to introspect here, as each module has a __file__ attribute which is the location of the source file, and we will use that to construct a path to the template files.
robaccia-bin
def createproject(args):
"""robaccia createproject <name>
Creates a new project directory structure.
The target directory must not exist.
"""
try:
name = args[0]
except:
sys.exit("Error: Missing required parameter <name>.")
if os.path.exists(name):
sys.exit("Error: Directory '%s' already exists" % name)
template_dir = os.path.abspath(
os.path.join(robaccia.__file__, "..", "templates", "project")
)
shutil.copytree(template_dir, name)
addview
At this point let's skip to our second scenario and implement the 'addview' command. We'll go back later and add the 'addmodelview' command.
We'd like to keep the cognitive load as small as possible. If you look at the original implementation of Robaccia, each view had to render it's own template:
!! This is the old way, what were trying to replace !!
import selector
import view
urls = selector.Selector()
urls.add('/blog/', GET=view.list)
urls.add('/blog/{id}/', GET=view.member_get)
!! This is the old way, what were trying to replace !!
def list(environ, start_response):
rows = model.entry_table.select().execute()
return robaccia.render(start_response, 'list.html', locals())
WSGICollection helps by adding an idiom and removing the need
to map each request URI and method to a WSGI application, but we
can do better. We can take robaccia.render()
and presume that every renderer will conform to that signature.
Since we have a convention for how files will be laid out, we can
do even more work, we can look up the template to render using
the name of the WSGICollection that was called, and the name of the
member function that was called.
The only piece of information we are missing is the file extension
of the template, so we will have to pass that in also.
What we want, for example, is that if we add a collection 'fred':
/views/fred.py /templates/fred/list.html /templates/fred/retreive.html
Then a GET to /fred/ will
end up calling views.fred.app.list(), and the template
/templates/fred/list.html will be rendered.
That's fine default behavior, but we need a way to signal whether we want the default rendering to occur, of the collection view member function has decided to over-ride the default behavior and do it's own processing.
In normal processing a wsgicollection member function returns an iterable. We can look for things besides iterables to indicate that we should look for a template and render it. The simplest thing is to look for a dictionary, since that is what you pass into a template to get rendered. We can also accept 'None' in the response and convert that into some sort of acceptable dictionary to be passed into the templating engine.
Here is the implementation for DefaultCollection, which implements the above design:
defaultcollection.py
from wsgicollection import Collection
import os
class DefaultCollection(Collection):
def __init__(self, ext, renderer):
Collection.__init__(self)
self._ext = ext
self._renderer = renderer
def __call__(self, environ, start_response):
response = Collection.__call__(self, environ, start_response)
if response == None:
if self._id:
response = {'id': self._id}
else:
response = {}
if isinstance(response, dict):
view = environ['wsgiorg.routing_args'][1].get('view', '.')
template_file = os.path.join(view, self._function_name + "." + self._ext)
return self._renderer(environ, start_response, template_file, response)
else:
return response
Note that we hand off most of the work to wsgicollection.Collection, and then if the response is a dictionary we look up the template and pass the name into the renderer. The only other thing to note is that the construtor now takes two new arguments, the template filename extension, and the renderer.
DefaultCollection now vastly simplifies our views if we just want the default templates rendered:
from robaccia.defaultcollection import DefaultCollection from robaccia import render class Collection(DefaultCollection): # GET /{view}/ def list(self, environ, start_response): pass # GET /{view}/{id} def retrieve(self, environ, start_response): pass # PUT /{view}/{id} def update(self, environ, start_response): pass # DELETE /{view}/{id} def delete(self, environ, start_response): pass # POST /{view}/ def create(self, environ, start_response): pass app = Collection('html', render)
To stop handling a particular URI, such as deleting a member of the collection, just remove the associated member function.
run
We are almost done with our first scenario. All we need now is a way to run our application. Since we based Robaccia on WSGI we can use wsgiref to run our application under a local web server for development purposes.
robaccia-admin
def run(args):
"""robaccia run
Start running the application under
a local web server.
"""
from dispatcher import app
from wsgiref.simple_server import WSGIServer, WSGIRequestHandler
robaccia.init_logging()
httpd = WSGIServer(('', 3100), WSGIRequestHandler)
httpd.set_app(app)
print "Serving HTTP on %s port %s ..." % httpd.socket.getsockname()
httpd.serve_forever()
Note again we know the WSGI app to load because of our file layout conventions. The last piece of the puzzle is how dispatcher.py routes the incoming requests to the right view.
dispatcher.py
from robaccia.wsgidispatcher import Dispatcher
from robaccia import deferred_collection
app = Dispatcher()
app.add('/{view:alnum}/[{id:unreserved}][;{noun:unreserved}]', deferred_collection)
A dispatcher.py is copied into every project so that you can customize it later if you want to do something besides the default everything-is-a-collection convention. Any URI templates added before the one that's already there will match first.
It's deferred_collection that does our lookup of the view to call.
deferred_collection()
def deferred_collection(environ, start_response):
"""Look for a views.* module to handle this incoming
request. Presumes the module has
an 'app' that is a WSGI application."""
# Pull out the view name from the template parameters
view = environ['wsgiorg.routing_args'][1]['view']
# Load the named view from the 'views' directory
m = __import__("views." + view, globals(), locals())
# Pass along the WSGI call into the given application
logging.getLogger('robaccia').debug("View: %s" % view)
return getattr(getattr(m, view), 'app')(environ, start_response)
We construct the view name from the incoming path and then load that module dynamically. Of course a little error handling, like returning a 404 if the module isn't found, would be good, but you get the idea.
So that finishes it, our first phase is complete. If we include a couple simple templates for 'list.html' and 'retrieve.html' then we can run the second scenario with this code:
joe@joe-laptop:~$ robaccia-admin createproject myproject joe@joe-laptop:~$ cd myproject/ /home/joe/myproject joe@joe-laptop:~/myproject$ robaccia-admin addview fred created views/fred.py created templates/fred/list.html created templates/fred/retrieve.html joe@joe-laptop:~/myproject$ robaccia-admin run Serving HTTP on 0.0.0.0 port 3100 ... localhost - - [24/May/2007 11:14:49] "GET /fred/ HTTP/1.1" 200 116
Pointing our browser at http://localhost:3100/fred/ gets us:
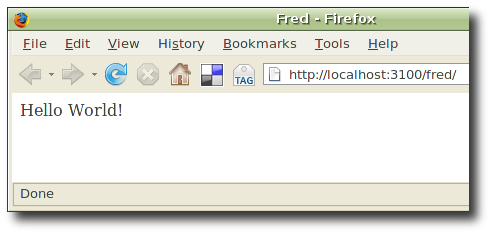
Phase Two - Model
Now let's get cracking on adding in the database.
If you know me, you know I'm not a huge fan of relational databases, I prefer my stores more scalable and my columns sparse, but let's not talk about that now. All of the next generation web frameworks rely on a relational database and this section will show how to do just that.
The very first thing we are going to need is a configuration file for the database, which we'll use dbconfig.py and throw that into the default project files so it is always present.
On top of the files we added for 'addview' we will add in a model, and some template code for adding and editing collection members.
DefaultModelCollection does everything that DefaultCollection does, but now we have a 'model' to keep track of. Those dictionaries are going from the model into templates. There is also a way to parse incoming request bodies.
defaultmodelcollection.py
from wsgicollection import Collection
import os
from robaccia import http200, http405, http404, http303
class DefaultModelCollection(Collection):
def __init__(self, ext, renderer, parser, model):
Collection.__init__(self)
self._ext = ext
self._renderer = renderer # converts dicts to representations
self._model = model
self._parser = parser # converts representations to dicts
self._repr = {} # request representation as a dict()
def __call__(self, environ, start_response):
response = Collection.__call__(self, environ, start_response)
if environ['REQUEST_METHOD'] in ['PUT', 'POST']:
self._repr = self._parser(environ)
if response == None:
primary = self._model.primary_key.columns.keys()[0]
view = environ['wsgiorg.routing_args'][1].get('view', '.')
template_file = os.path.join(view, self._function_name + "." + self._ext)
method = environ.get('REQUEST_METHOD', 'GET')
if self._id:
if method == "POST" and "_method" in
self._repr and self._repr["_method"] in ["PUT", "DELETE"]:
method = self._repr["_method"]
del self._repr["_method"]
if method == 'GET':
result = self._model.select(self._model.c[primary]==self._id
).execute()
row = result.fetchone()
if None == row:
return http404(environ, start_response)
data = dict(zip(result.keys, row))
return self._renderer(environ, start_response, template_file,
{"row": data, "primary": primary})
elif method == 'PUT':
self._model.update(self._model.c[primary]==self._id
).execute(self._repr)
return http303(environ, start_response, self._id)
elif method == 'DELETE':
self._model.delete(self._model.c[primary]==self._id).execute()
return http303(environ, start_response, "./")
else:
print method
return http405(environ, start_response)
else:
if method == 'GET':
result = self._model.select().execute()
meta = self._model.columns.keys()
data = [dict(zip(result.keys, row)) for row in result.fetchall()]
return self._renderer(environ, start_response, template_file,
{"data": data, "primary": primary, "meta": meta})
elif method == 'POST':
self._model.insert(self._repr).execute()
return http303(environ, start_response, ".")
else:
return response
Note that the constructor takes a renderer, a parser, and a model. The renderer takes dictionaries and turns them into response bodies. The parser takes incoming request bodies and turns them into dictionaries. We already have an HTML renderer, all we need to do form processing is something that takes incoming 'application/x-www-form-urlencoded' data and converts it into a dictionary, which is easy to come by.
We need to update our 'view' to handle the 'edit' and 'new' forms, which just means adding 'get_edit_form()' and 'get_new_form()' functions to the view. The templates are also pretty simple. Here is the updated 'list.html':
list.html
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:py="http://genshi.edgewall.org/" >
<head>
<title>Fred</title>
</head>
<body>
<p><ahref=";new_form">New</a></p>
<p py:for="row in data">
<p py:for="key, value in row.iteritems()">
<b>$key</b>: $value
</p>
<ahref="${row[primary]}">${row[primary]}</a>
<hr/>
</p>
</body>
</html>
And now we're able to meet our initial design:
joe@joe-laptop:~$ robaccia-admin createproject myprj
joe@joe-laptop:~$ cd myprj/
/home/joe/myprj
joe@joe-laptop:~/myprj$ robaccia-admin addmodelview employees
created views/employees.py
created models/employees.py
created templates/employees/list.html
created templates/employees/retrieve.html
created templates/employees/get_edit_form.html
created templates/employees/get_new_form.html
joe@joe-laptop:~/myprj$ vim models/employees.py
joe@joe-laptop:~/myprj$ cat models/employees.py
from sqlalchemy import Table, Column, Integer, String
import dbconfig
table = Table('employees', dbconfig.metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(250)),
Column('title', String(250)),
Column('office_number', Integer()),
)
joe@joe-laptop:~/myprj$ robaccia-admin createdb
joe@joe-laptop:~/myprj$ robaccia-admin run
Serving HTTP on 0.0.0.0 port 3100 ...
The database is initially empty. Click on New to create a new member in the collection.
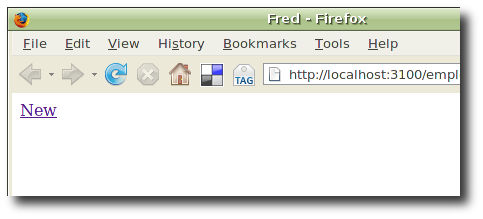
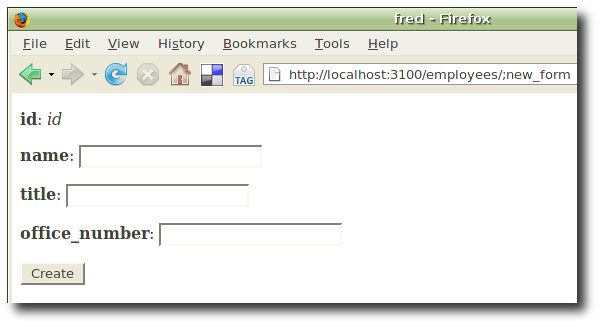
Creating a new employee.
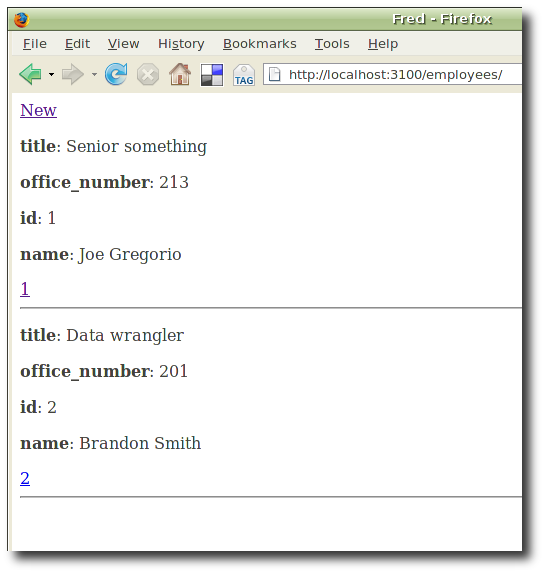
Our collection list afer adding couple new employees. Note the link to individual employees.
From an individual collection member we can edit and delete the employee.
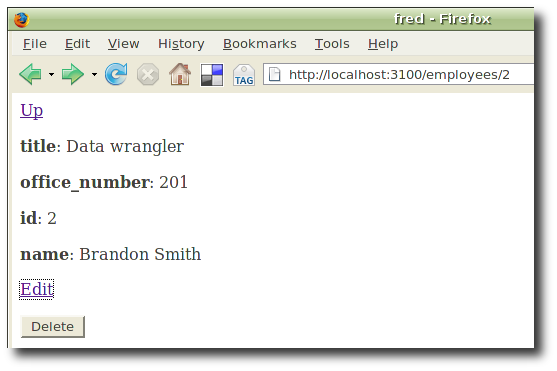
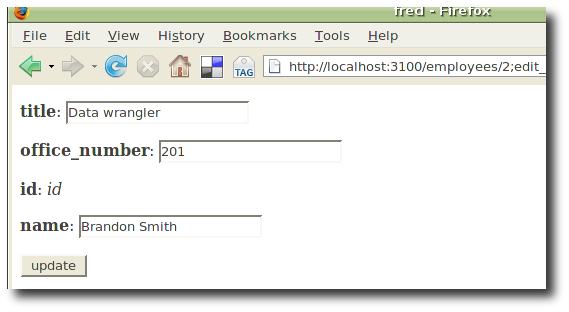
A form for editing the employee.
Lessons
We came up with a rather simple database to web framework, but in reality haven't lost any flexibility over the original Robaccia. All the pieces of URI dispatching, views and templates are present, all we did was pave the happy path.
We paved the happy path by embracing the following constraints:
- All resource fit into a collection.
- A single URI path structure.
- A fixed model interface: SQLAlchemy.
- A fixed project layout.
- WSGI as method of communication between components.
- A single media-type for any single view. (You can have different views with different media-types that use the same model.)
- Not really mentioned explicitly, but all the configuration was done through Python files.
Observations
The code so far has renderers and parsers for HTML and HTML forms, but we could easily add support for JSON or Atom.
There isn't much that ties us to SQLAlchemy; just DefaultModelDispatcher and the initial files put down by 'robaccia addmodelview'. We could easily switch out to another ORM, or even drop the RDBMS and move to another kind of data store.
There is a whole slew of stuff that hasn't been done like handling changes to the database, deployment, security, large collections that require paging, etc. Those are all solvable problems, and not the point of this exercise, which was to demonstrate applying constraints to reduce cognitive and manual load to create a Rails/Django-like web framework.
The code is now available on code.google.com. If you run it under Python 2.5 you will only need to install SQLAlchemy and Genshi. For Python 2.4 you will also need to install wsgiref.
Posted by sky on 2007-05-25