 Joe Gregorio
Joe Gregorio
Perfetto and the SQL processing built into trace_processor are both fantastic, but two of the most important parts of that SQL processing are not well documented, at least for my simple brain.
The first feature is SPAN_JOIN which is described as:
Span join is a custom operator table which computes the intersection of spans of time from two tables or views.
There is a nice diagram showing how the spans are combined:
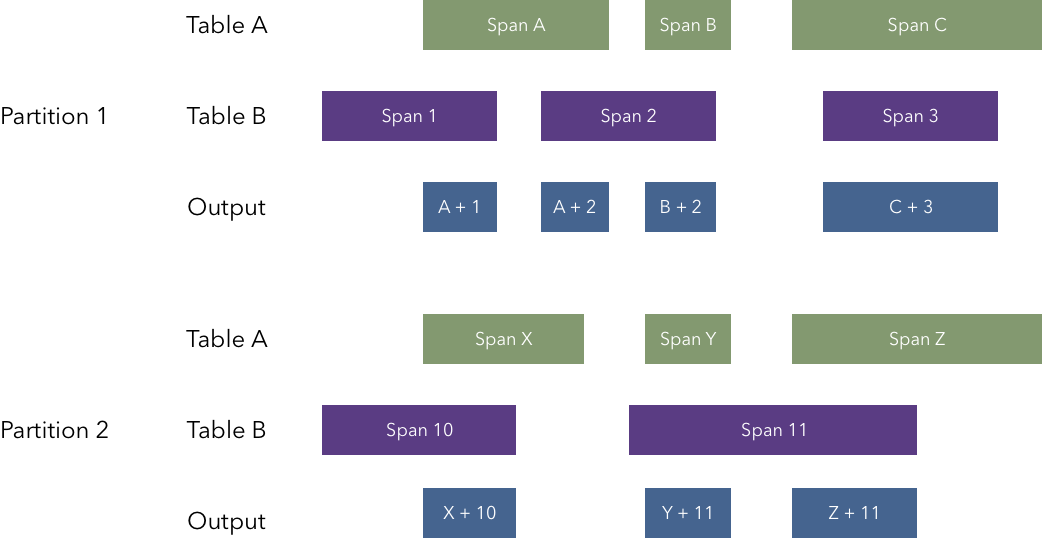
But the part of the missing documentation here is the definition a span, which is a row in a table that has both ’ts’ and ‘dur’ columns, where ’ts’ is a timestamp, and ‘dur’ is the size of that span in the same units as ’ts’.
Now if you have two tables (or views on a tables) that have ’ts’ and ‘dur’ columns you can use SPAN_JOIN to create a new view that has all the intersecting spans.
For example, let’s look at one unit test from SPAN_JOIN:
If we have table f with the following values:
| ts | dur | f_val |
|---|---|---|
| 100 | 10 | 44444 |
| 110 | 50 | 55555 |
| 160 | 10 | 44444 |
And table s with the following values:
| ts | dur | s_val |
|---|---|---|
| 100 | 5 | 11111 |
| 105 | 5 | 22222 |
| 110 | 60 | 33333 |
Then if we SPAN_JOIN them together via:
CREATE VIRTUAL TABLE sp USING span_join(f, s);
The we’ll get the following values for view sp:
| ts | dur | f_val | s_val |
|---|---|---|---|
| 100 | 5 | 44444 | 11111 |
| 105 | 5 | 44444 | 22222 |
| 110 | 50 | 55555 | 33333 |
| 160 | 10 | 44444 | 33333 |
But there are more than slices stored in Perfetto tables, what are we to with tables that are simply timestamped measurements?
That’s where the second feature comes in, SQLite LEAD, which allows you read values from the next row in the table.
To see this in action let’s say we had this table f:
| ts | f_val |
|---|---|
| 100 | 44444 |
| 110 | 55555 |
| 160 | 44444 |
| 200 | 66666 |
We can create a dur column in a view using LEAD:
CREATE TABLE f (ts BIG INT PRIMARY KEY, f_val BIG INT);
INSERT INTO
f
VALUES
(100, 44444),
(110, 55555),
(160, 44444),
(200, 66666);
CREATE VIEW f_slices AS
SELECT
ts,
f_val,
LEAD(ts) OVER (
ORDER BY
ts
) - ts as dur
FROM
f;
SELECT
*
FROM
f_slices;
Running the above will generate the following table for the f_slices view:
| ts | f_val | dur |
|---|---|---|
| 100 | 44444 | 10 |
| 110 | 55555 | 50 |
| 160 | 44444 | 40 |
| 200 | 66666 | [NULL] |
And now since it has both ts and dur columns it can be used as a input to
SPAN_JOIN.
One thing to note here is that the very last row has NULL for its duration,
since there is no following row to compare against. You might need to filter out
rows with NULL values depending later calculations.
There are plenty of other options for SPAN_JOIN and LEAD, but hopefully with
this intro those explanations will make more sense.