 Joe Gregorio
Joe Gregorio
There has been much talk today, and in the far past, of how to automatically handle syndication subscription. The conversation was first brought up and thoroughly discussed by Greg Reinacker. The issue has resurfaced on the [atom-syntax] mailing list. Now there are a small contingent of folks pushing for a new uri scheme called 'feed:' that would enable syndication subscription. Creating a new URI scheme is a bad idea, don't do it.
So what is the alternative to hooking onto a new URI scheme? Well, the correct way to this is to hook onto the mime-type. Mime-types are the fundamental way types of files are identified in HTTP, and SMTP and in other areas too but well just concentrate on HTTP for now. Atom feeds have the mime-type of 'application/atom+xml'.
How do we go about using mime-types to connect an Atom feed sitting on a web server to a client aggregator application? There are two sides to the equation, the client side, and the server side.
Server Side
In order for this to work the Atom feed must be server up with
a mime-type of 'application/atom+xml'. There are two general
cases to consider. Either the file is server up statically or it is
generated on the fly by a CGI program. The CGI generated case is the
easiest of the two. When producing the output from the CGI program
just include the Content-type: header with the correct
mime-type:
Content-type: application/atom+xmlThe case for statically served files is only slightly
more complicated, in this case you just need to let Apache
know about the new mime-type. You do that by using the
AddType directive, which maps a file extension to a mime-type.
In the directory that you are storing the Atom feeds in
add the following line to your .htaccess file:
AddType application/atom+xml .atomNow any file stored with a .atom file extension will
be served up with the mime-type of 'application/atom+xml'.
Client Side
The server side of the equation was easy, things get a little more complicated on the client side. To make things easier we'll assume you are running under Windows, people in the know of how to do these things under Mac and unix should feel free to speak up in the comments. Under Windows the mapping of mime-types to applications is handled through the registry. So let's walk through the process of setting up the registry to handle the Atom mime-type. To make the discussion concrete here is a little stub of a C program that is going to stand in for our aggregator:
#include <stdio.h>
#include <conio.h>
int main(int argc, char * argv[]) {
printf("Atom Handling Application.");
printf("The Atom Feed is located at: %s\n", argv[1]);
getch();
return 1;
}When called this program just prints the command line argument it was passed and then waits for the user to press any key before the program completes. If you have Microsoft's C++ compiler installed you can build it with:
cl -GX handle.cOr if you have the Borland compiler installed:
bcc32 handle.cEither way you end up with an executable handle.exe.
For the rest of this dicussion we'll assume that handle.exe
is installed at the fixed location C:\AtomHandler\handle.exe.
New values are then added to the Registry to map the mime-type
application/atom+xml to our handler application.
Just like under Apache mapping of mime-types is done using file
extensions even if a file with that extension is never involved.
I'll explain that in a minute. First we hook into the file extension
.atom. The following three snippets are from
exported sections of the registry. You would not actually
hand edit or manually add these items to your registry,
instead the application installation program needs to
take care of this step.
[HKEY_CLASSES_ROOT\.atom]
@="atom_file"
This binds the .atom extension to a
name, a kind of indirection, of "atom_file". Now we
need to add values to the registry to indicate
what to do when encountering a file with this
extension:
[HKEY_CLASSES_ROOT\atom_file]
@="Atom Syndication Program"
[HKEY_CLASSES_ROOT\atom_file\shell]
[HKEY_CLASSES_ROOT\atom_file\shell\open]
[HKEY_CLASSES_ROOT\atom_file\shell\open\command]
@="\"C:\\AtomHandler\\handle.exe\" %1"Now this will run our handle application and pass the name of the file in as the first argument on the command line. The last step is to map the mime-type to the file extension. This is done with the following keys:
[HKEY_CLASSES_ROOT\MIME\Database\Content Type\application/atom+xml]
"Extension"=".atom"
Now you can see why the file extension is necessary, even if it is never used, that is, even if you never have a file with the extension ".atom" on your hard drive, you still need to register the extension so you have some thing to map through, from the mime-type to the extension and finally to the handling application. Now, at least under my testing with Mozilla and IE under Windows, both applications will now use this information to launch the correct application. Unfortunately IE comes up with rather ominous warning box the first time you click on an Atom feed:
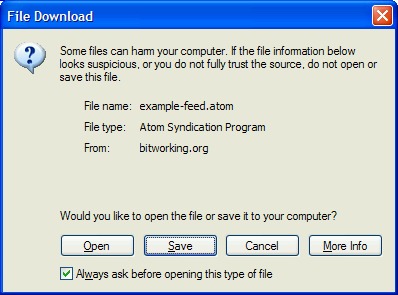
Mozilla comes up with a similar, but less ominous dialog box the first time an Atom feed is encountered.
What happens is that the browsers download the file into a temporary location and then pass the name of that file to our handler application. At this point, if an aggregator was setup as the handler of the Atom feed it could parse the feed and ask the user if they wished to subscribe. Well...except that the aggregator can't subscribe to the feed because all it has is the feed, what it really needs is the URI of the feed. That is, the Atom feed the user just clicked on is stored on disk and the actual URI that the browser downloaded the file from is not avialable to the handling application. So to make this scheme work, the URI of the Atom feed needs to be included in the Atom feed itself. This is another place where the new 'link' tag syntax shines. If you look at the example feed I have provided it contains just such a tag, as a child of the feed element:
<link rel="self"
href="http://bitworking.org/projects/atom/examples/example-feed.atom"/>
Note that the link tag uses the attribute 'rel' with a value of
'self' to uniquely indicate that the 'href' attribute contains the
URI of this Atom feed. Aggregator subscription
to Atom feeds can be handled seemlessly without
registering a new URI scheme. If the feed: URI
scheme were followed it looks like it
would actually require
registering such a scheme with each browser installed
on the computer.
Note: No matter what scheme ends up being used, the user must be prompted to confirm that they wish to subscribe to the feed. What the browser is doing is just retrieving a representation with GET and Agents do not incur obligations by retrieving a representation.
If you would like to test this out I have an example feed setup at http://bitworking.org/projects/atom/examples/example-feed.atom.
Further Reading
Update
I have updated the text above and the example to reflect the final version of Atom 1.0.
Posted by Joe on 2003-12-06
Joe - thanks for go where many of would fear to tread (the Windows registry).
Roger - one of the justifications for Atom is to get beyond the limitations of RSS. But in this particular case, I don't see why RSS couldn't use the same solution.
Posted by Danny on 2003-12-06
Joe: That's a 'nother kettle of fish. :)
Danny: I agree, something similar could be cooked up for RSS... and I'd be happy to play along if it happened. But I have nothing but sympathy for those running servers and clients that don't have the necessary flexibility, and I wouldn't lose one moment's sleep if the aggregator developers decide to just skip it all and push forward with feed: or subscribe:.
Posted by Roger Benningfield on 2003-12-06
Why did you pick "start" as the link relationship? Would it not be better as "subscribe"?
What rel type would you use to point to the first in a collection of archived feeds (cv: rel="next")?
Posted by Eric Scheid on 2003-12-06
Thanks for that link. It also led me to @profile, which then confused me with 'scheme's for @content (instead of schemes for @name, then I remembered we're talking about <link> not <meta>. But I digress.
"Start -- Refers to the first document in a collection of documents. This link type tells search engines which document is considered by the author to be the starting point of the collection."
Ah-huh? I think I see your logic now... The subscription address is where you find the first document in the collection of documents which will be created some time in the future (as the feed is updated).
The fact that the subscription address is where you can find the most recently added postings, in a continuing series, and thus semantically might be called "last", or more properly "last, for now", and not where you would find the first postings in such a collection, is neither here nor there ;-)
Unless you are retro-actively posting to your feed, that is.
Posted by Eric Scheid on 2003-12-07
Posted by Joe on 2003-12-07
So it looks like "Start" can be confusing ;-) My own preference would be for a core registry of Atom-specific terms in Atom's namespace. The Atom documentation could even say that Atom.Subscribe is equivalent to HTML.Start.
btw, given the way people have been using it in the examples, I guess it's reasonable to take rel="something"
to be equivalent to rel="Atom.something"
which will also be the same as
http://atomsnamespace.org/schema#something
Posted by Danny on 2003-12-07
Posted by Mark on 2003-12-07
Posted by Danny on 2003-12-08
Posted by Graham on 2003-12-08
Think of the feed as a WinAmp playlist file, and the RSS as a shoutcast stream.
You don't need a new feed protocol, just a new mime-type and a file that contains the RSS location.
Posted by Christian Mogensen on 2003-12-08
It's a How-To. I have no interest in exploring which method is easier. A new URI scheme, as I explain in the article, and has also been explained repeatedly on [atom-syntax] and [www-tag] is the wrong thing to do. This is a How-To article. It shows you how-to properly use mime-types on the worlds most popular web server and on Windows with both Mozilla and IE.
Posted by Joe on 2003-12-08
Posted by Joe on 2003-12-08
If I had a blog nobody would read it, which is no different to not having a blog. Good thing I don't think you're a blog-snob ;-)
Point taken on HTML spec. My mistake.
I wouldn't use 'start' to point to the resource to watch for updates, I'd probably use 'subscribe' (or another string). I'd use 'start' to provide guidance to a robot as to where would be a good place to start crawling, and then 'next' to point to the next resource (etc). It would be good if the robot doesn't have to back track to the 'start' to find more stuff.
On 'subscribe', just to muddy the waters, I wouldn't assume it points to the resource to watch for updates either. It could point to a html page which asks for money first. In which case I suppose I could use @type to specify that the @href in the <link> points to a resource which should be handled by a web browser.
Posted by Eric Scheid on 2003-12-08
This discussion is also occurring on the W3C www-tag mailing list, where the consensus seems to be that if a helper application needs to get the original URL, then the user agent should also be passing it, as well as the representation.
In other words, don't create a new scheme, don't create a new mime type just for subscriptions, just pass the original URL to the helper.
Of course, this doesn't help in the short term. One suggestion was that the RSS feed include a link to it's own URL, which would allow the aggregator to subscribe to it.
Malcolm
Posted by Malcolm on 2003-12-10
Joe: Can you clarify/explain why you say that "the user must be prompted to confirm that they wish to subscribe to the feed"?
My reading of the web architecture draft you link to is that your server MAY NOT infer anything from the fact that my client retreived the feed representation (e.g.: it shouldn't add me to a ('push') email list).
That's very different from saying that my client MAY NOT then do something with that representation once retrieved (e.g.: add it to a local list, thereby subscribing me to a ('pull') Atom feed).
Rather than being a matter of web architecture, isn't that latter option down to me, firmly in the realm of which client I choose to use and how I choose to configure/empower it?
Posted by David Bruce on 2003-12-10
You are correct, the web architecture document refers to only obligations accrued at the server side of doing a GET.
Posted by Joe on 2003-12-12
I'm currently looking at a similar approach for initiating a WebDAV mount from HTML content (for instance, for Mozilla to be able to initiate opening the Microsoft Webfolder client).
I got it working nicely under Windows, but I'm not so sure about how to write/register the application on MacOS X / Safari. Did anybody try that for the Atmom feed thingy?
Julian
Posted by Julian Reschke on 2004-04-02
Joe: None of this is particularly helpful for the vast majority of syndication efforts, which are now RSS-based, and will continue to be so well into the future.
IOW, you're proposing an Atom solution to a problem much bigger than Atom.
Posted by Roger Benningfield on 2003-12-06